从词向量到概念发现,知识图谱让机器更加理解人类语言
鲁迅先生说,“人类的悲欢并不相通,我只觉得他们吵闹”。而人工智能与人类智能之间的巨大鸿沟则主要源于语言的差异。机器语言是0,1二进制;相反,人类语言则姿态万千、丰富多彩。如何才能让机器更好地理解人类语言,从而为我们所用呢?
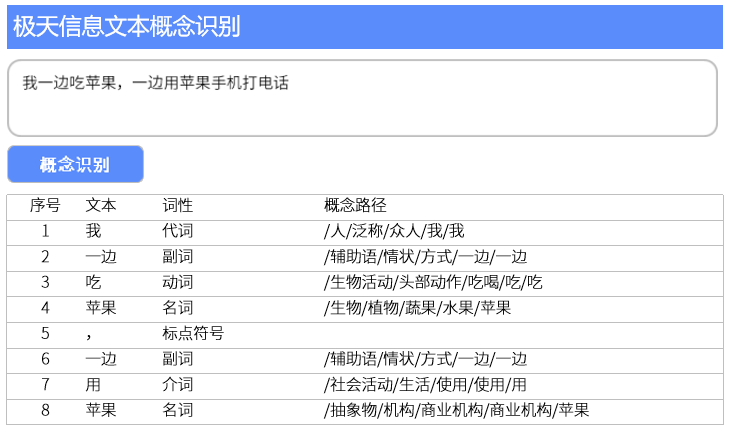
人类语言中存在大量的多义词、同义词等,同一个词在不同语境下有不同的概念,又或者明明是同一个概念却可以有多个词进行表示。比如“我一边吃苹果,一边用苹果打电话。”这句话中“苹果”一词出现了两次,人们基于自己的常识可以迅速判断出两个“苹果”所代表的不同意思。机器能否跟人一样聪明呢?通过极天信息的“文本概念识别”工具进行识别(如下图),通过概念路径可以发现,计算机也能够正确识别出前一个“苹果”指水果,后一个“苹果”则代表公司品牌。
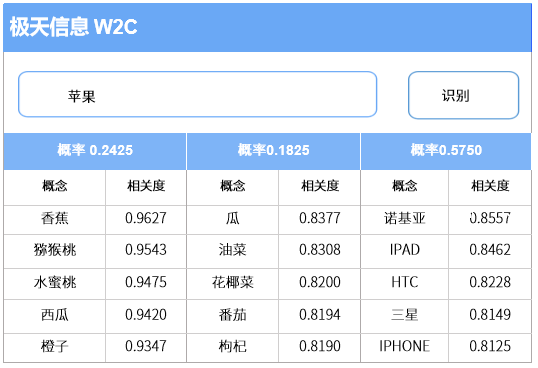
“苹果”一词是否存在更多新含义?要知道,在实际应用中,我们往往要面对完全不熟悉的领域,怎么样快速通过领域知识训练找到所有核心概念是重中之重。利用极天信息Word2concept(简称W2C)概念发现工具进行识别,结果得出“苹果”一共有三个概念结果,除了水果、公司品牌之外,还有蔬菜的概念。此外还可以发现当前训练的数据集中,“苹果”的三种概念,公司品牌所指出现的概率是最高的,且与“诺基亚”“三星”有较高的相关度。
那么,面对语义理解精准度越来越高的要求,而当前业界通用的词向量却无法解决一词多义的情况下,极天信息是如何做到让机器也具备“常识库”从而能够准确识别不同的概念呢?
事实上,自2007年以来,极天信息便坚持潜心研究语义网(Ontology)与知识图谱(Knowledge Graph)的构建和应用。Ontology是共享概念模型的明确的形式化规范说明(1998, Studer),其定义了概念及概念和概念之间的关系,使得人与人之间、人与计算机之间能基于共享的概念进行语言交流。历经多年研发,极天信息成功推出通用知识图谱SemNet,并形成了“软件+方法+模型”的三位一体知识图谱服务体系,让企业可以体验到“开箱即用”的知识图谱服务,进一步降低了知识图谱构建的门槛,开展了丰富的智能化应用。知识工程创始人Edward Feigenbaum曾说:“Knowledge is the power in AI system”。正是得益于极天信息在知识图谱上的多年积累,机器才能如上述所示表现如此出色,能够保证智能化应用的高精准度,提高语义理解的质量。
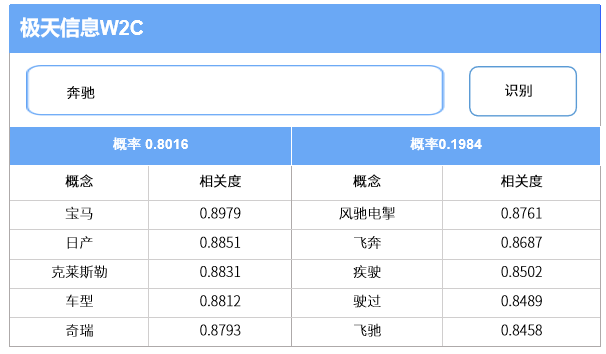
而知识图谱构建的基础工具之一就是W2C。利用W2C概念发现工具,可以快速发现新概念,以及相似概念之间的相关度,从而发现概念与概念之间的关系,最终辅助构建领域知识图谱。比如“奔驰”一词,通过W2C进行概念识别,可以发现作为公司品牌出现的概率达80%,作为动词出现的概率则仅为20%;在公司品牌这一概念中,其与“宝马”的相关度又是最高的,有助于梳理出各个概念之间的关系。这对于新领域的自然语言处理任务来说,将会带来十分可观的效果。
总的来说,W2C概念发现工具尤其适合处理复杂语义环境下的自然语言处理任务,使用也更加方便与高效。现在,极天信息将这一工具免费开放使用,希望能够助推各个行业的人工智能应用更加广泛、更加深入。